


Inflexões e Implicações
O fim das certezas na AI - e o que isto significa para o mercado.

Junte-se a mais de 9.700 empreendedores e investidores assinando o Sunday Drops:
A edição de hoje é apoiada pela Onfly.

A Onfly é um software vertical revolucionando a experiência de viagens corporativas e despesas, para as empresas e funcionários. Ela nasceu para atender pequenas e médias empresas, e agora também oferece o Onfly Corporate, uma solução personalizada para grandes contas, com atendimento dedicado e total personalização.
O resultado? Mais controle, segurança, dados em tempo real e até 35% de economia nas viagens das empresas. Não à toa, empresas como PicPay, Hotmart, Heinz e Blip já estão entre as mais de 1.800 empresas que confiam na Onfly.
Saiba mais sobre como a Onfly pode ajudar sua empresa:
Inflexões e Implicações
Há uma cena fascinante em O Jogo da Imitação em que Alan Turing e sua equipe percebem, de repente, que conseguiram decifrar o Enigma da Alemanha Nazista. É um momento decisivo, onde tudo muda em segundos, transformando o curso da história. A guerra tomaria um rumo diferente e, sem que soubessem, ali também nasceria a base da computação moderna.
Momentos assim são raros, porém redefinem as regras do jogo quando acontecem. A Deep Seek talvez não tenha proporção para ser o Enigma da nossa geração, mas, seu impacto questiona um paradigma que já era tido como verdade: de que a corrida da inteligência artificial estava restrita a bilionários com acesso a clusters gigantes de GPUs. E, como toda boa inflexão, ela abre espaço para uma nova onda de inovação.
A inflexão premedita uma maré de mudança. No livro Pattern Breakers, Mike Mapples descreve que são nesses momentos que janelas únicas de oportunidades se abrem para empreendedores: a conectividade em massa dos smartphones deu origem às redes sociais, o GPS foi revolucionário desde o iPhone 4 ao Uber, os computadores pessoais foram importantes para a Microsoft.
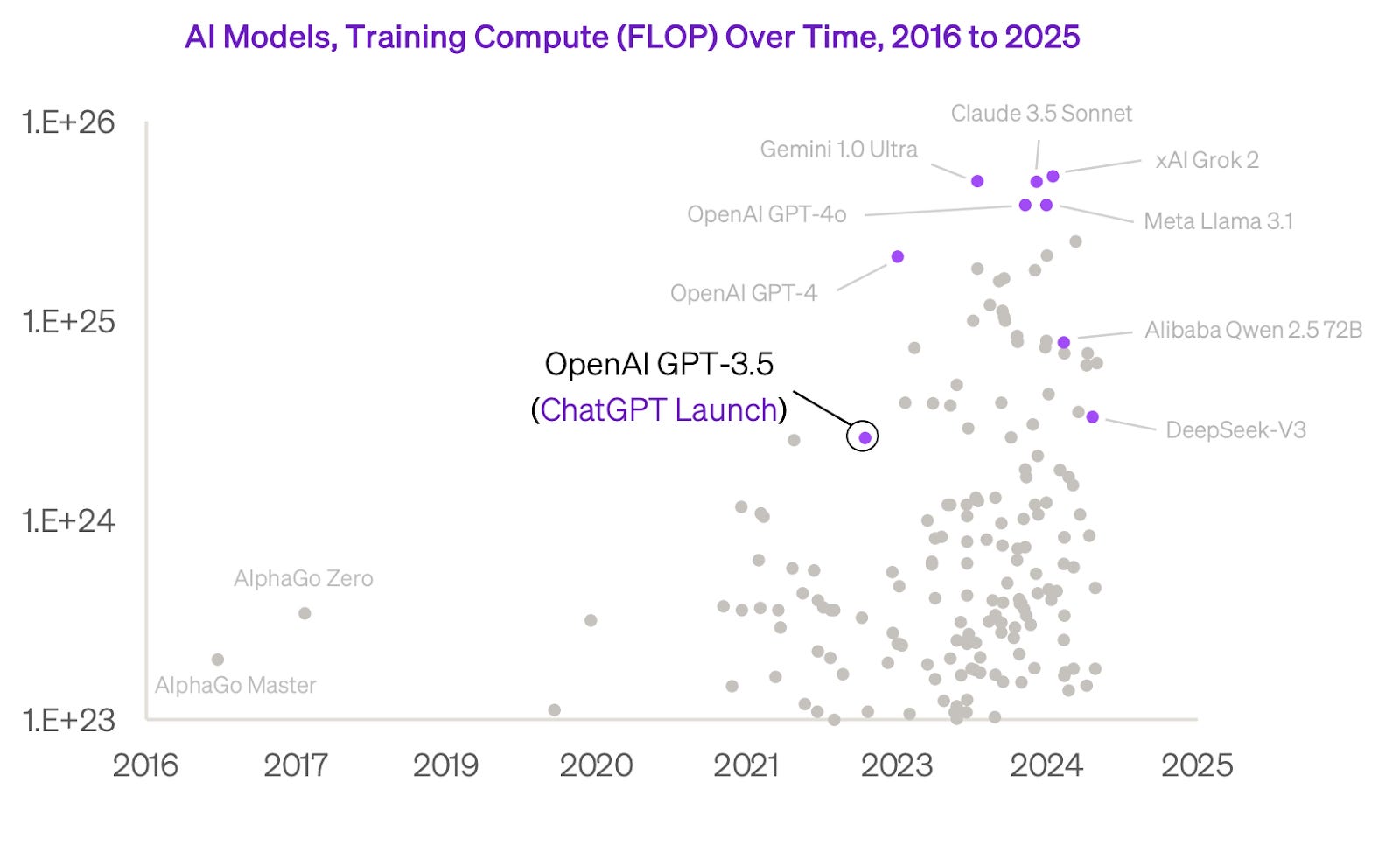
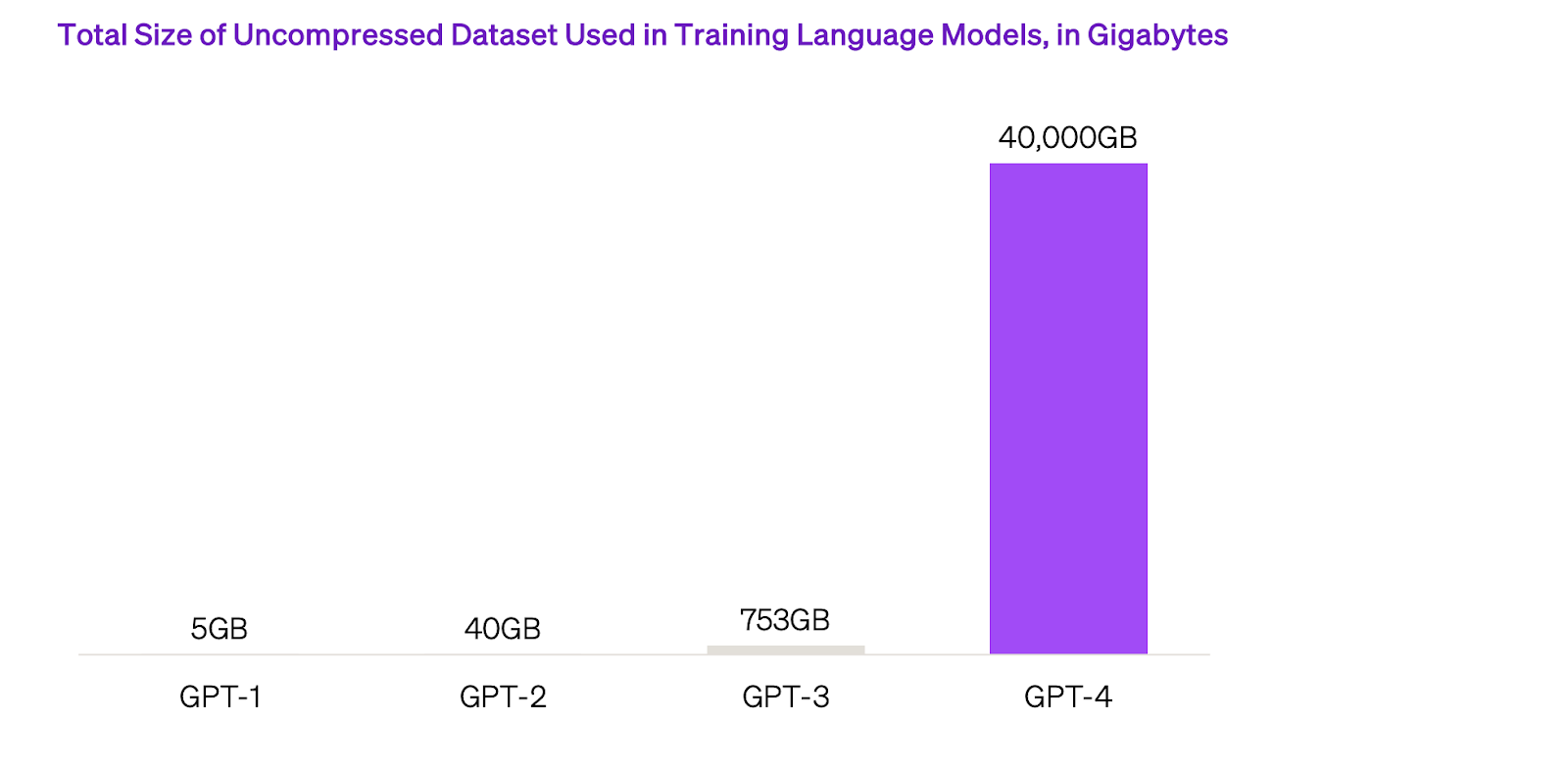
No que tange às inflexões e inteligência artificial, parece haver uma lei que rege os avanços recentes da inteligência artificial - as leis da escala. Ela demonstra que quanto mais dados e poder computacional, maior a complexidade e a capacidade dos modelos. Por essa razão, o tamanho dos modelos foi exponencializado nos últimos anos, assim como a quantidade de poder computacional empregado.
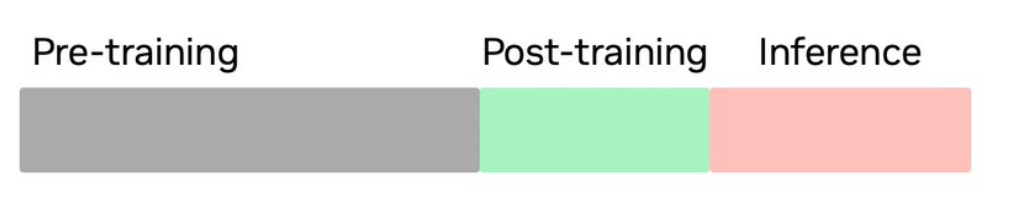
Quando usamos o ChatGPT ou qualquer outro modelo, ele (simplificando) é o resultado de três etapas principais:
Pré-treinamento: Um processo que envolve alimentar o modelo com enormes quantidades de dados e utilizar poder computacional de ponta combinado com software avançado. Isso torna o modelo altamente eficiente em prever a resposta correta com base no contexto.
Pós-treinamento: Uma etapa de ajuste fino, em que o modelo é refinado para moderar as respostas, de modo que sejam melhores para as expectativas humanas.
Inferência: O momento em que o modelo aplica tudo o que aprendeu para responder perguntas ou resolver problemas em tempo real.
No pré-treinamento e no pós-treinamento, é necessário usar GPUs de última geração, e é aqui que são usados todos aqueles clusters gigantes de IA, que custam bilhões de dólares. Até hoje, em termos de foco, as empresas de modelo de IA investiram principalmente nesses dois aspectos, afinal os retornos em termos de performance foram gigantes.

O grande ponto do mercado de IA é que, à medida que todos os dados do mundo foram varridos e colocados dentro de um supercomputador, os resultados dos modelos não avançaram na velocidade anterior, tornando-se um consenso que a lei da escala está chegando a um plateau. Como podemos ver abaixo, estamos diante de uma curva S, que sinaliza uma estabilização.
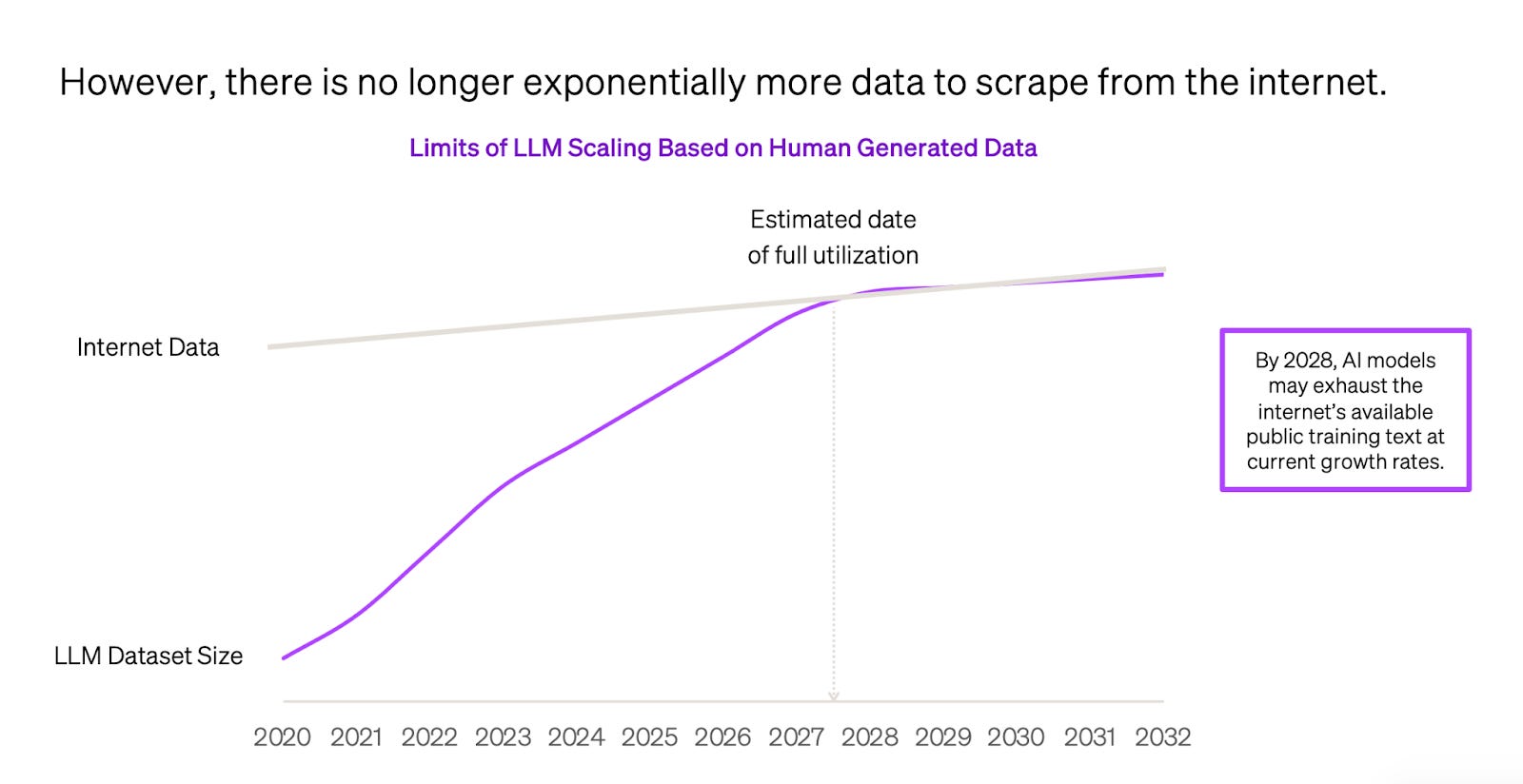
Ilya, que cofundou a OpenAI e é um dos grandes cientistas do tema, comentou que a era de simplesmente escalar modelos está se esgotando e que todo mundo está buscando o próximo grande avanço no que se refere a modelos. Sam Altman, em abril de 2023, já antecipava que o progresso não viria em tornar os modelos ainda maiores, mas sim em fazê-los de forma inteligente.
Dito isso, muitas pessoas inteligentes e com muito dinheiro continuaram investigando o problema. A alternativa viável foi investir mais tempo no processo de inferência, que basicamente se resume a construir melhores sistemas com a quantidade de dados que já temos. Com isso, surgiu o "test-time computing", um conceito poderoso que se tornou relevante no mundo da IA. Ele faz com que os modelos gastem mais tempo pensando e simulando respostas até escolher a melhor. Esse tempo se provou eficiente: os segundos a mais que o modelo pensa geram resultados superiores quanto à qualidade da resposta. A resultante será mais investimentos em poder computacional para a parte de inferência, que, por acaso, são menores do que o gasto em pré-treinamento. Imagine que o gasto recorrente (Opex) passa a se tornar mais relevante na equação.
Um marco deste novo mundo foi o lançamento do ChatGPT-o1 em setembro. Ele é um modelo destilado do GPT-4, ou seja, ele se aproveita de tudo que foi gasto para produzir o modelo base. Sua característica especial é que ele gasta muito mais tempo em inferência - por isso é chamado de um modelo de "raciocínio". Sua lógica é da "Cadeia de Pensamentos", na qual ele é incentivado a seguir uma série de passos antes de responder qualquer pergunta. Ele realmente "pensa" mais e, com isso, traz resultados melhores e mais acurados, especialmente em tarefas mais complexas. O grande ponto da inferência é que, diferentemente do pré-treinamento, ela precisa de menos poder computacional para ser executada. Se você é assinante do ChatGPT Plus e usa o o1, você percebe que a qualidade do modelo é superior e o número de alucinações, muito menor. Daniel Kahneman popularizou o framework de que há duas formas de pensar, o Sistema I e II. O II é mais analítico e profundo. É uma boa analogia argumentar que estamos avançando para o Sistema II.

A lógica de alavancar o poder computacional e acrescentar dados parece estar se esgotando e, no momento, o desafio é pensar sobre como fazer mais com menos. O Google também lançou seu modelo de raciocínio, o Gemini 2.0 Flash, e a DeepSeek lançou o R1, como vocês devem estar cansados de ler.
A consequência imediata disto, como vocês devem imaginar, é uma impressão de commoditização dos LLMs. No momento em que modelos destilados com foco em inferência conseguem ter resultado superior, isto significa que a próxima etapa não está em desenvolver algo grandioso e muito caro, mas sim em desenvolver outras partes do sistema.
A corrida do ouro
A competição na IA lembra uma corrida do ouro. Aprendi com Chris Yeh no Blitzscaling Ventures que landgrab é uma das principais estratégias para dominar novos mercados. Basicamente, é sobre capturar rapidamente usuários ou territórios, tornando difícil para concorrentes tomá-los de volta, porque quem chega primeiro, ganha. Esse termo remete à corrida por commodities, como ouro ou petróleo, e é uma "janela de oportunidade". Ela se encaixa no mundo da IA, afinal, quem chegar primeiro a uma tecnologia muito avançada terá retornos em proporções espetaculares.
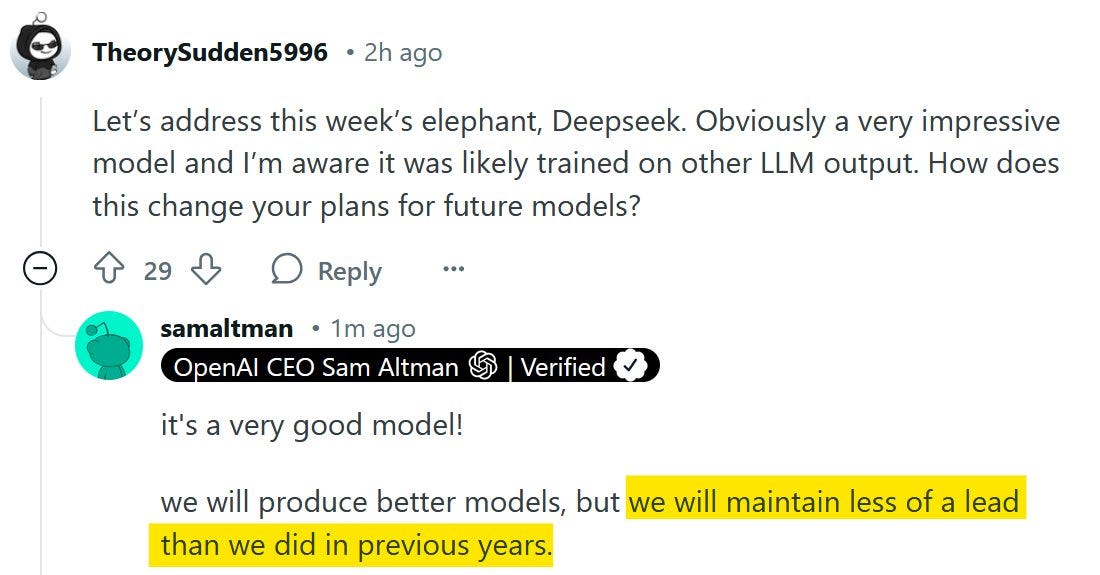
Nesta corrida ao ouro, os valores investidos são bem altos: nos últimos 5 anos, mais de US$ 370 bilhões foram aplicados no setor. Somente em 2025, a OpenAI anunciou o projeto Stargate, com um custo estimado de US$ 500 bilhões, enquanto a Meta decidiu investir US$ 60 bilhões em infraestrutura para IA. Estamos a beira de um salto de investimentos para treinar esses modelos:
Esta corrida ao ouro da IA se transformou em um clássico dilema do prisioneiro: mesmo que a cooperação beneficie todos, cada player é incentivado a gastar mais e mais, temendo ficar para trás. O resultado é este nível de investimento sem precedentes na história da tecnologia, concentrado nas mãos de poucos players.
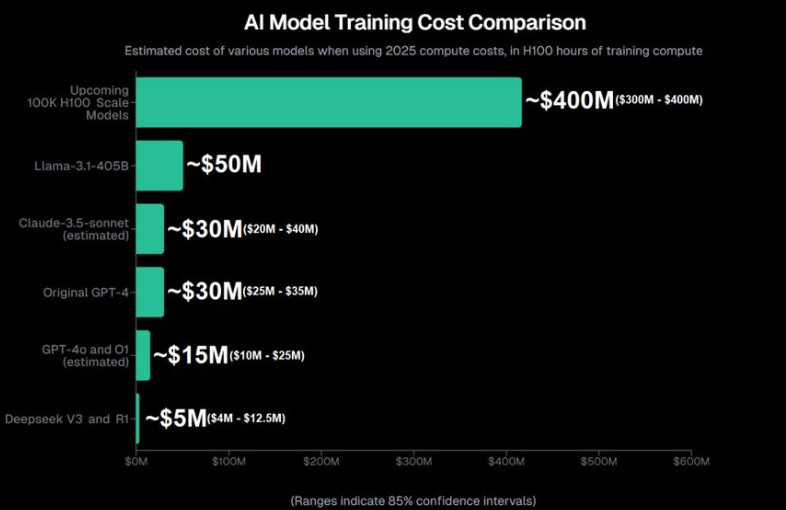
Contudo, toda corrida do ouro envolve riscos. Um dos mais significativos é a volatilidade do valor da "commodity". No contexto da IA, o retorno potencial de um hardware — como uma fábrica de chips da NVIDIA — pode ser extraordinariamente alto, mas também pode, em um cenário adverso, tornar-se completamente inútil. Como o potencial de ROI é tão grande, quem está no landgrab não está nem aí para o preço, afinal, o foco está no prêmio final. A tarefa de otimizar fica para empresas à margem que não conseguiriam chegar primeiro ao pote de ouro, como a DeepSeek. Este é o ponto que poucos entenderam entre todas essas notícias: o grande destaque dessa história não é o fato de o modelo ser mais eficiente e acessível. Afinal, as empresas nessa corrida pelo ouro têm negócios sólidos o suficiente para absorver esses custos sem comprometer suas operações.
O que importa é a mudança de status quo.
DeepSeek e a mudança de paradigmas
Em junho de 2023, Sam Altman visitou a Índia. O seguinte diálogo aconteceu (em tradução livre):
Pergunta da Plateia: “Então, dá para uma startup daqui competir construindo modelos fundacionais? Um time de três engenheiros brilhantes, com 10 milhões em vez de 100 milhões, poderia criar algo realmente relevante? ”
Sam Altman: “Olha, você pode usar os modelos já existentes, como o ChatGPT e outros, mas se quiser construir um do zero, como faz?”“A verdade é que vamos te dizer que é completamente impossível competir conosco treinando modelos fundacionais.”
Pergunta: “Então não vale a pena tentar?”
Sam Altman: “Na real, é o seu trabalho tentar mesmo assim. Acho que é praticamente um caso perdido…
Essa resposta envelheceu mal.
A DeepSeek não revolucionou a IA. Ela não é melhor que OpenAI, Anthropic ou Gemini. A ascensão do modelo R1 foi o marco de toda uma mudança que já estava acontecendo na IA. Ela mostrou que a categoria de modelos fundacionais é muito mais ampla do que se imaginava, e que mesmo em um ambiente de escassez (graças ao chip ban) e com um time muito menor (reportado como tendo menos de 200 pessoas) e até usando uma linguagem menos modernas, é possível construir algo poderoso que está apenas alguns meses atrás do melhor modelo do mundo.
O que a DeepSeek fez de excepcional (e aqui estou parafraseando meus colegas especialistas) é a capacidade de executar ideias antigas muito bem. Para ilustrar, vamos relembrar um dos marcos da IA: a vitória do AlphaGo, em 2015, quando derrotou o campeão mundial do jogo Go. O AlphaGo aprendeu a jogar por meio do reinforcement learning, um método no qual a máquina simula inúmeros jogos contra si mesma, aprimorando suas estratégias a cada partida. Essa abordagem permitiu que evoluísse sem depender de instruções humanas, contrastando com os modelos de linguagem atuais, que tradicionalmente contam com feedback humano para afinar a previsão da próxima palavra.
O grande feito da DeepSeek foi justamente conseguir aplicar o reinforcement learning de forma autônoma nos LLMs, eliminando a necessidade de intervenção humana durante o treinamento e demonstrando um novo patamar de eficiência e escalabilidade.
As implicações do DeepSeek:
Mostrou o poder do Open Source.
Algo fascinante aconteceu quando a Meta lançou o LLaMA e a DeepSeek disponibilizou seus modelos: eles transformaram o que era um jogo de bilionários em uma corrida muito mais interessante.
Vejamos: open source é um tipo de modelo disponível na internet para qualquer um baixar e usar. É como se as empresas estivessem dizendo: "Olha, gastamos bilhões treinando esse cérebro artificial, agora você pode pegá-lo emprestado e criar algo novo em cima". É como quando você pega uma receita base de bolo e adiciona seus próprios ingredientes para criar algo único.
O que faz os modelos da DeepSeek e do LLaMA tão importantes é a democratização do acesso ao que há de mais avançado em IA. Qualquer pessoa pode baixar esse "cérebro" que foi treinado com milhares de GPUs e começar a criar soluções em cima. É o que chamamos de destilação do modelo - você pega aquele "cérebro emprestado" e o especializa para seu caso específico.
Disponibilizar algo assim muda completamente o jogo. Quando você tem modelos poderosos disponíveis gratuitamente, as empresas são forçadas a competir em outras dimensões. Não é mais sobre quem tem mais dinheiro para treinar modelos, mas sim quem consegue criar os melhores produtos e soluções usando esses modelos como base. É como o que aconteceu com os smartphones: o Android ser open source não impediu a Apple de ter sucesso, mas criou um ecossistema inteiro de inovação que beneficiou todo mundo. Na IA, está acontecendo algo parecido - enquanto as gigantes continuam investindo bilhões em seus modelos proprietários, uma nova geração de startups está surgindo, construindo soluções incríveis em cima dos modelos open source.
E isso é só o começo. Com mais modelos open source surgindo, veremos uma explosão de inovação vinda de lugares inesperados. Times pequenos, mas altamente técnicos, poderão criar soluções de nicho extremamente poderosas. É como se estivéssemos democratizando o acesso à eletricidade no início do século XX - ninguém precisava mais construir sua própria usina, bastava se conectar à rede e criar produtos inovadores. Isso vai habilitar uma série de produtos reais com muito valor.
Mostrou que os LLMs estão sendo mais commoditizados
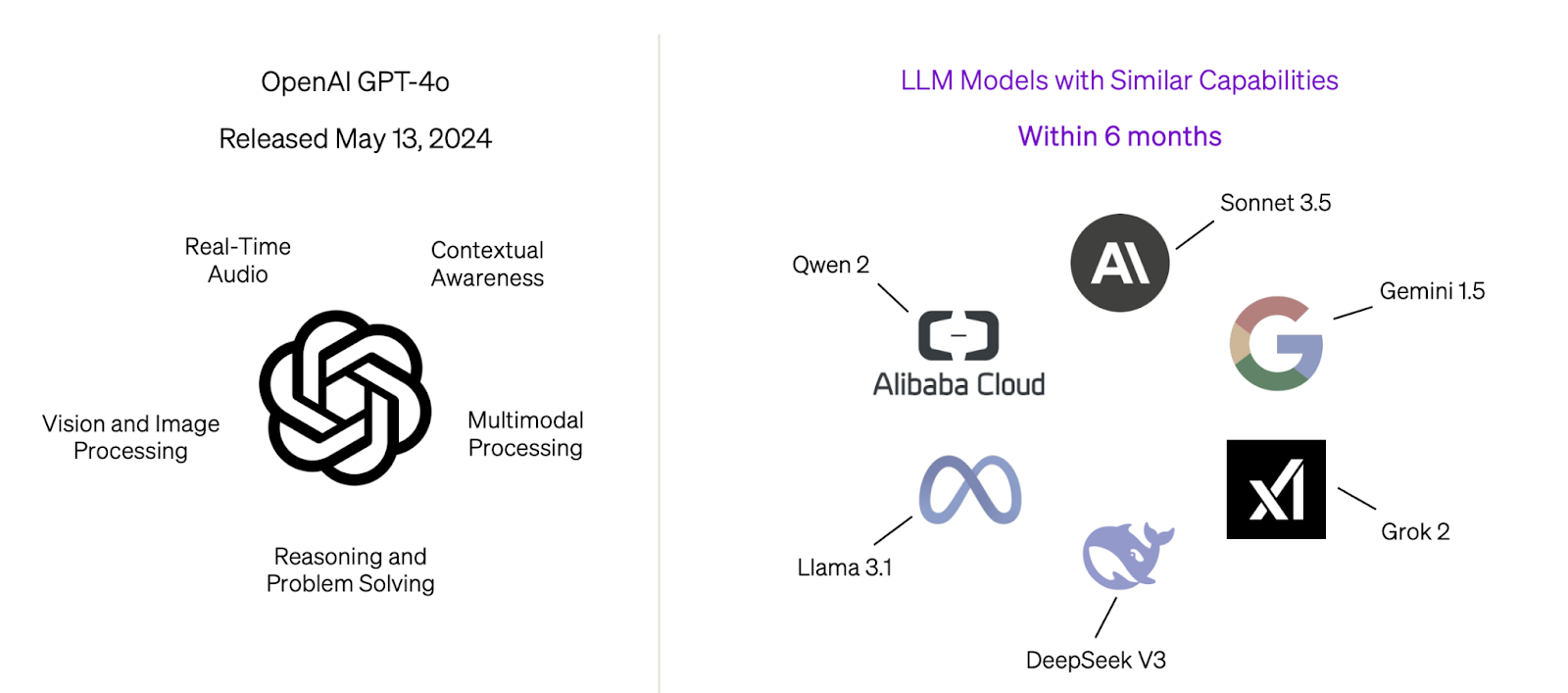
À medida que as inovações acontecem na esfera da inferência e do pós-treinamento, mais poder está em empresas que se capacitam nessa área. A consequência é um movimento em prol da verticalização da IA, no qual times técnicos trabalham em inferências para resolver muito bem uma parte do problema e geralmente estão fora da camada do pré-treinamento, ou seja, pode ser feito por times após o modelo estar disponível. O próprio Jensen Huang diz que a inferência será 1 bilhão de vezes mais importante no mundo da IA . Outro ponto que reforça essa tese de que LLMs serão mais commoditizados é que os produtos são parecidos. Mesmo com todo capital investido, a diferença entre modelos é questão de meses. Explico: o Gemini está três meses atrás da OpenAI, a Anthropic quatro meses.
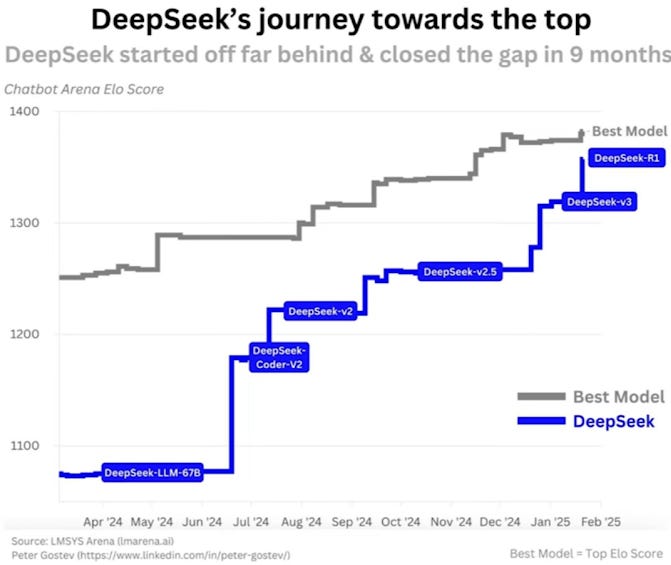
A velocidade de evolução dos modelos da DeepSeek foi impressionante:
A dinâmica está mudando para diferenciação baseada em inteligência. O que fará um produto ser melhor não é apenas a capacidade cognitiva, mas sim o produto e a distribuição. O que fez o modelo R1 da DeepSeek ficar em primeiro lugar na App Store foi o modelo de negócios inovador subsidiado: ele abriu o aplicativo de forma gratuita e foi a primeira vez que muitas pessoas tiveram acesso a modelos de raciocínio sem custo (que são modelos melhores). O que faz um escritor ou programador usar o Claude em vez do GPT é porque o modelo é melhor para essa área. Como toda a história da internet, o valor está nas aplicações e no valor gerado.
Mostrou que há um futuro mais democrático em soluções verticais.
O mundo de soluções verticais é outro cenário que ganhou força com esta inflexão. Enquanto os grandes modelos de linguagem são generalistas por natureza - como um médico que sabe um pouco de tudo - a DeepSeek mostrou que há um caminho viável para construir inteligências mais especializadas e focadas. É como se tivéssemos saindo de uma era pura de “apenas hospitais gerais" para uma era que soma-se a “clínicas especializadas”.
Um caso que exemplifica perfeitamente esta tendência é a Hyperplane, que acompanhei de perto antes de sua aquisição pelo Nubank. Em vez de tentar competir com OpenAI ou Anthropic construindo um modelo para todas as tarefas possíveis, eles focaram em desenvolver um modelo especializado para o mercado financeiro que performa melhor por ser especializado.
Esta abordagem vertical está se provando um caminho promissor: vemos startups desenvolvendo modelos específicos para análise jurídica, diagnóstico médico, descoberta de drogas e dezenas de outras verticais. Cada uma delas aproveita o conhecimento profundo de seu domínio para criar algo que os modelos generalistas, mesmo com todo seu poder computacional, têm dificuldade em replicar.
O mais interessante é que esta especialização não requer os mesmos níveis astronômicos de investimento dos modelos generalistas. Com técnicas de destilação e fine-tuning, é possível pegar um modelo base open source e especializá-lo profundamente em um domínio específico. É como ter acesso a um cérebro brilhante e treiná-lo para ser excepcionalmente bom em uma área específica, em vez de tentar fazê-lo dominar todo o conhecimento humano.
Como escreveu Edmar Ferreira: "Organizações com profundo conhecimento em um domínio específico podem aproveitar essas técnicas de RL criando conjuntos de avaliação personalizados e ambientes de treinamento. Por exemplo, startups da área da saúde podem desenvolver cenários que imitam a tomada de decisões clínicas, enquanto instituições financeiras podem criar funções de recompensa baseadas em resultados de gerenciamento de risco."
Mostrou que sistemas homogêneos são frágeis.
Nassim Taleb lembra que sistemas homogêneos e monopolizados se tornam frágeis. O sistema estava frágil: todas as empresas tinham mais ou menos as mesmas estratégias, boa parte delas tinha sede nas mesmas cidades e os mesmos fornecedores. A inovação precisou vir de um outsider e, por isso, o sistema se desestabilizou. Sistemas muito homogêneos são frágeis por concentrarem riscos em um único ponto de falha — no caso, a crença de que apenas poucos players de infraestrutura dominariam toda a IA, o que estava de fato acontecendo (e que vai continuar).
Considerações finais
A história das startups sempre foi sobre underdogs mudando o jogo. Mas, por algum motivo, aceitamos que IA seria diferente, de que seria um clube fechado para bilionários. A DeepSeek mostrou que às vezes precisamos de alguém de fora do Vale do Silício para nos lembrar disso e que novas curvas S continuam a aparecer.
E agora? Bem, o campo está muito mais interessante:
Open source democratizando acesso a modelos base
Inferência permitindo inovação com menos capital
Times pequenos podendo competir em nichos específicos
Produto e distribuição voltando a ser mais importantes que capital
Para fundadores e investidores, a expectativa é a melhor possível. Se antes o jogo era dominado por quem tinha US$ 500 bilhões em clusters de GPUs, agora a vantagem está em quem consegue inovar e criar produtos que sejam realmente impactantes. Por outro lado, a velocidade dessa evolução torna o futuro imprevisível. O que hoje parece revolucionário pode se tornar obsoleto em questão de tempo.
Como sempre acontece na tecnologia, no fim das contas, não é sobre quem tem mais dinheiro, mas sim sobre quem consegue resolver os problemas reais da melhor forma. O tabuleiro está sendo redefinido.
Estamos diante de um ponto de inflexão.
Obrigado a Edmar Ferreira, Felipe Meneses e Júlia Garcia pelas sugestões.
Se gostou, compartilhe.
Ou assine abaixo para receber no seu email aos domingos um artigo especial sobre tecnologia, startups e investimentos:
Live sobre Deep Seek que fiz com o Edmar Ferreira (vale a pena ouvir!):